
코드를 배포했다고 끝이 아닙니다. 진짜 시작은 서비스가 사용자 손에 전달된 이후부터입니다. ‘서버가 살아있는가?’를 넘어 ‘안에서 어떤 일이 벌어지고 있는가?’를 투명하게 들여다보는 힘, 바로 **옵저버빌리티(Observability)**입니다. 오늘은 현대 백엔드 운영의 표준인 Prometheus와 Grafana를 활용해 장애를 사전에 방지하고 성능을 실시간으로 추적하는 시스템을 구축해 보겠습니다.

[그림 1] 시스템 내부를 꿰뚫어 보는 힘, 옵저버빌리티의 시각적 개념
1. 모니터링 vs 옵저버빌리티: 무엇이 다른가?
전통적인 **모니터링**은 “CPU 사용량이 90%를 넘으면 알려줘” 같은 정해진 지표(Metrics) 중심입니다. 반면 **옵저버빌리티**는 로그(Logs), 메트릭(Metrics), 트레이싱(Tracing)이라는 세 개의 기둥을 통해 서비스의 상태를 입체적으로 분석합니다. 장애가 발생했을 때 단순히 ‘문제가 있다’는 것을 넘어 ‘왜 문제가 생겼는지’를 추론할 수 있게 해주죠.
2. Prometheus와 Grafana: 모니터링계의 환상적인 복식조
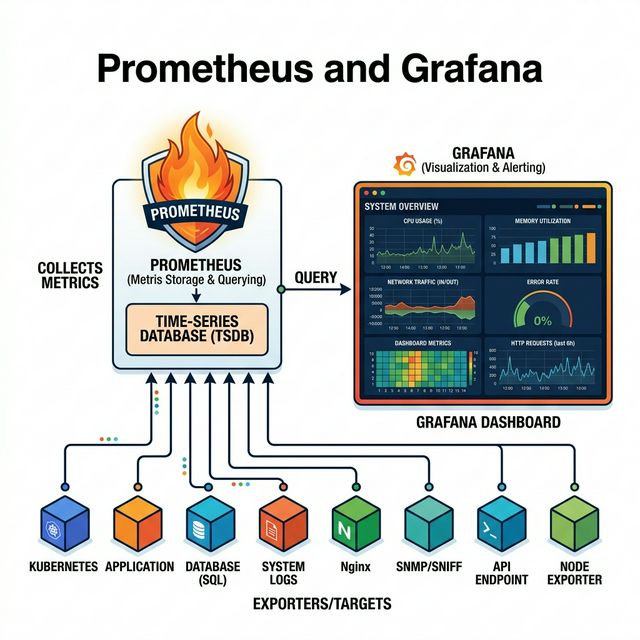
[그림 2] 데이터 수집(Prometheus)과 시각화(Grafana)의 조화로운 아키텍처
**Prometheus**는 시계열 데이터베이스(TSDB)이자 수집기입니다. 서버가 데이터를 보내는 대신, Prometheus가 주기적으로 서버를 찔러서(Scrape) 데이터를 가져오는 ‘Pull’ 방식을 사용합니다. 이렇게 쌓인 수치 데이터들을 **Grafana**라는 강력한 대시보드 도구를 통해 사람이 보기 편한 그래프와 차트로 그려내는 것이죠.
3. 실전 적용: Spring Boot와 Actuator 연동
Spring Boot 환경에서는 `micrometer` 라이브러리를 통해 간단히 연동할 수 있습니다.
// build.gradle 설정
implemention 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'io.micrometer:micrometer-registry-prometheus'
// application.yml
management:
endpoints:
web:
exposure:
include: "prometheus"
이제 `/actuator/prometheus` 엔드포인트를 통해 JVM 상태, HTTP 요청 수, 응답 시간 분 분포 등의 방대한 메트릭이 노출됩니다. Prometheus는 이 주소를 15초마다 긁어가며 우리의 시스템을 감시하게 됩니다.
4. 알람 설정: 장애보다 빠른 대응의 핵심
단순히 그래프를 보는 것은 수동적인 대응입니다. Prometheus의 **Alertmanager**를 활용하면 특정 조건(예: 5xx 에러율 5% 이상 지속) 발생 시 즉시 슬랙(Slack)이나 이메일로 알림을 보낼 수 있습니다. 자고 있는 개발자를 깨우는 대신, ‘사전 경고’를 통해 골든 타임을 확보하는 것이 모니터링의 궁극적인 존재 이유입니다.
마치며: 보이지 않는 것을 믿지 마세요
운영 중인 시스템의 지표를 보지 못하는 것은 눈을 감고 고속도로를 운전하는 것과 같습니다. 비즈니스가 커질수록 더욱 견고한 관제 탑이 필요합니다. 오늘 소개한 Prometheus와 Grafana로 여러분의 서비스를 더 투명하고 안전하게 만들어 보시기 바랍니다.