
사용자가 늘어나고 데이터가 쌓일수록 서비스는 느려지기 마련입니다. ‘왜 이렇게 응답이 늦지?’라는 질문에 대부분의 신입 개발자는 서버 사양을 높이는 것을 먼저 생각합니다. 하지만 문제의 90%는 데이터베이스(DB)에 있습니다. 오늘은 시스템 부하를 근본적으로 해결하고 API 성능을 수십 배 끌어올리는 DB 인덱싱과 쿼리 최적화의 정수를 다뤄봅니다.

[그림 1] 느린 쿼리와 최적화된 DB의 성능 차이 극명한 대비
1. 인덱스(Index)는 왜 필요한가? (Full Scan의 공포)
DB에 100만 건의 데이터가 있다고 가정해 봅시다. 인덱스가 없다면 특정 사용자를 찾기 위해 DB는 처음부터 끝까지 모든 데이터를 뒤져야 합니다. 이를 **Full Table Scan**이라고 합니다. 책에 ‘찾아보기(색인)’가 없다면 원하는 단어를 찾기 위해 첫 장부터 끝까지 읽어야 하는 것과 같습니다. 인덱스는 바로 이 ‘찾아보기’를 미리 만들어두어 검색 속도를 혁신적으로 줄여줍니다.
2. 기술적 원리: B-Tree 구조의 이해
대부분의 RDBMS(MySQL, PostgreSQL 등)는 **B-Tree(Balanced Tree)** 구조를 사용하여 인덱스를 관리합니다. 상위 노드에서 하위 노드로 가지를 쳐가며 데이터를 찾아가는 방식이죠.
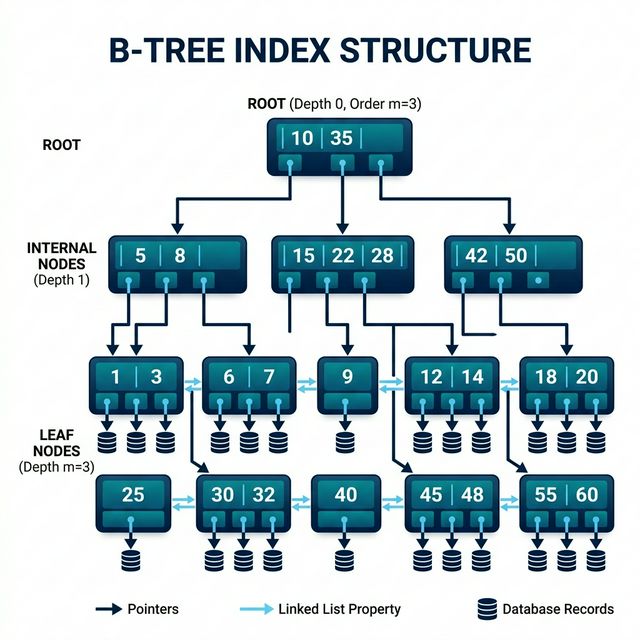
[그림 2] 정렬된 노드를 통한 고속 탐색, B-Tree 알고리즘의 구조
이 구조 덕분에 100만 개의 데이터가 있어도 단 20번 내외의 비교만으로 원하는 값을 찾아낼 수 있습니다. 하지만 주의할 점이 있습니다. 인덱스를 추가하면 ‘조회’는 빨라지지만, 데이터를 넣거나(Insert) 수정할(Update) 때마다 인덱스 트리도 함께 갱신해야 하므로 **’쓰기 속도’**는 오히려 느려집니다. 무분별한 인덱스 생성이 독이 되는 이유입니다.
3. 실전 쿼리 튜닝: 복합 인덱스와 실행 계획(Explain)
두 개 이상의 컬럼을 묶어 인덱스를 만드는 **’복합 인덱스(Composite Index)’**를 쓸 때는 순서가 중요합니다. ‘성별’처럼 중복도가 높은 값보다 ‘이름’처럼 고유한 값이 앞에 올 때 성능이 극대화됩니다.
// [Bad] 인덱스를 타지 못하는 잘못된 쿼리 SELECT * FROM users WHERE YEAR(created_at) = 2024; // [Good] 인덱스를 100% 활용하는 쿼리 SELECT * FROM users WHERE created_at >= '2024-01-01' AND created_at < '2025-01-01';
쿼리 성능을 확인하려면 반드시 `EXPLAIN` 명령어를 사용하여 DB가 내 쿼리를 어떻게 해석하는지 확인해야 합니다. `type`이 `ALL`이라면 즉시 인덱스를 검토해야 하는 신호입니다.
4. 성능 개선의 결과: 비포와 애프터
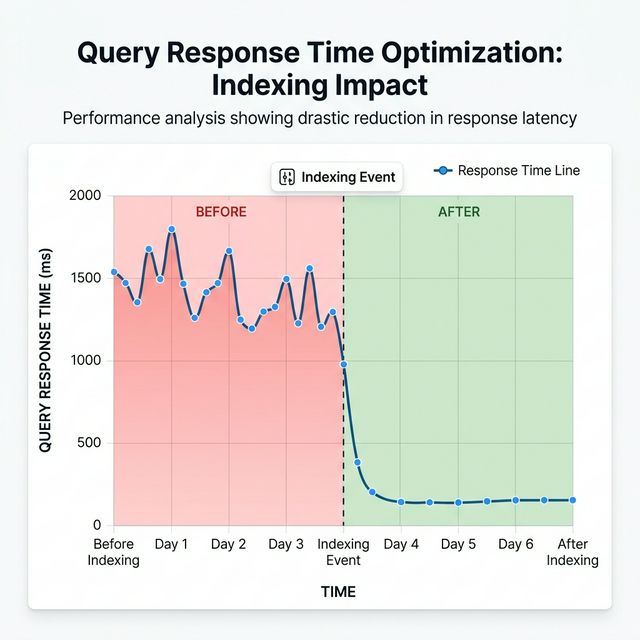
[그림 3] 적절한 인덱싱 적용 후 쿼리 응답 시간의 드라마틱한 감소
실제 서비스 리팩토링 과정에서 인덱스 최적화만으로 메인 API의 응답 시간을 **1500ms에서 50ms로** 줄였습니다. 인프라 비용 추가 없이 소프트웨어적 해결만으로 얻어낸 쾌거였습니다.
5. 고차원적 전략: 샤딩(Sharding)과 파티셔닝
데이터가 수억 건 단위를 넘어가면 단일 DB로는 한계가 옵니다. 이때는 데이터를 물리적으로 쪼개는 **'파티셔닝(Partitioning)'**이나 여러 대의 서버로 나누는 **'샤딩(Sharding)'**을 고려해야 합니다. 이는 설계 단계부터 데이터 분포를 아주 정밀하게 분석해야 하는 고난도 작업입니다.
마치며: 데이터는 거짓말을 하지 않습니다
성능 최적화는 감이 아니라 **'지표'**로 말해야 합니다. 느린 쿼리 로그(Slow Query Log)를 수시로 모니터링하고, 아키텍처의 병목을 찾아내는 습관이 고수와 하수를 가르는 결정적 차이입니다. 여러분의 서비스에서 가장 무거운 쿼리는 무엇인가요? 오늘 바로 분석을 시작해 보세요.