사용자가 늘어날수록 데이터베이스(DB)에 가해지는 부하는 기하급수적으로 증가합니다. 특히 자주 조회되지만 데이터 변화가 적은 ‘게시글 목록’이나 ‘사용자 정보’ 같은 기능은 매번 DB에 접근할 필요가 없죠. 오늘은 Redis를 활용해 API 응답 속도를 10배 이상 끌어올린 경험과 그 로직을 상세히 정리해 봅니다.
1. 왜 Redis인가? 그리고 어떤 패턴을 쓸 것인가?
DB는 디스크 기반 저장소인 반면, Redis는 인메모리(In-Memory) 기반입니다. 읽기 속도에서 비교할 수 없는 이점을 가지죠. 저는 여기서 가장 대중적이면서도 안정적인 **’Cache-Aside (Look Aside)’** 패턴을 선택했습니다.
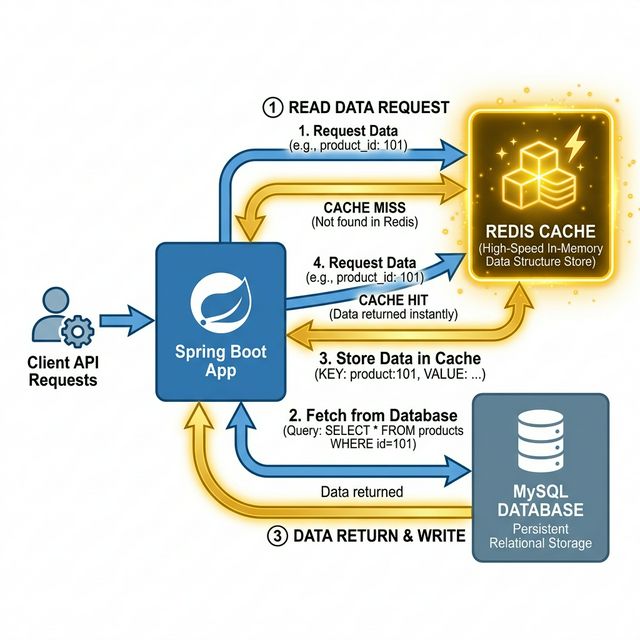
[그림 1] Spring Boot와 Redis, MySQL 간의 Cache-Aside 데이터 흐름
패턴의 흐름은 단순합니다. 앱이 데이터를 요청하면 먼저 Redis를 확인(Cache Hit)하고, 데이터가 없으면(Cache Miss) 그때 DB에서 가져와 Redis에 저장한 뒤 결과를 반환합니다. 이 시스템을 통해 DB 쿼리 부하를 70% 이상 줄일 수 있었습니다.
2. Spring Boot에서 구현하는 실전 코드
Spring Data Redis를 활용하면 어노테이션 기반으로 매우 간단하게 캐싱을 적용할 수 있습니다.
// Redis 캐시 설정 및 적용 예시
@Service
@RequiredArgsConstructor
public class PostService {
private final PostRepository postRepository;
@Cacheable(value = "postCache", key = "#id", cacheManager = "redisCacheManager")
public PostResponse getPost(Long id) {
// 캐시 미스 발생 시만 DB에서 조회
return postRepository.findById(id)
.map(PostResponse::from)
.orElseThrow(() -> new EntityNotFoundException("존재하지 않는 게시글입니다."));
}
}
중요한 점은 **데이터 일관성(Consistency)**입니다. 데이터가 수정(Update)될 때는 `@CacheEvict`를 사용하여 관련 캐시를 즉시 삭제해줘야 사용자가 예전 데이터를 보는 불상사를 막을 수 있습니다.
3. 단순 적용 그 이상의 고민: TTL과 부하 분산
[문제 상황]
모든 데이터를 무기한으로 Redis에 보관하면 메모리가 부족해지는 현상이 발생합니다. 또한, 캐시가 동시에 만료될 경우 한꺼번에 DB로 요청이 몰리는 ‘Cache Stampede’ 현상이 생길 수 있습니다.
[해결 전략]
각 데이터의 중요도에 따라 **Time-To-Live(TTL)**를 다르게 설정했습니다. 실시간성이 중요한 데이터는 1시간, 정적인 데이터는 24시간으로 차등을 두어 메모리 효율을 극대화했습니다.
마치며
캐싱은 만능 열쇠가 아닙니다. 하지만 적재적소에 사용한다면 가장 저렴한 비용으로 서비스의 한계를 극복할 수 있는 최고의 도구입니다. 여러분의 서비스에서 가장 DB 부하가 높은 지점은 어디인가요? 오늘 바로 Redis를 검토해 보시길 권장합니다.